製品・サービス情報
|
|
| データマイニングサービス(マイクロアレイ) / 解析内容の詳細 |
フィルジェンでは、大好評の解析ソフトウェア「Microarray Data Analysis tool」の無償提供に加え、マイクロアレイの各種データ解析をサポートする「データマイニングサービス」もご提供しています。
これまで、「データマイニングサービスは、内容・価格がわかりにくく、申し込みしづらい。」と感じていたお客様のために、内容がわかりやすく、さらに必要な解析項目だけ選択でき、加えて安価な価格でご利用頂けるサービスをご用意しました。
「解析フローチャート」をご参照頂ければ、どの解析項目を選択すればよいかを、ご理解頂くための手助けになると思います。
 遺伝子(タンパク質)を分類したい 遺伝子(タンパク質)を分類したい
|
発現プロファイルのクラスタリング解析サービスでは、発現データの分類を目的として、発現プロファイルの類似性に基づきデータを複数のグループ(クラスター)に分けるサービスを行います。このクラスタリングには、階層型クラスタリングと非階層型クラスタリングがあります。
【階層型クラスタリングサービス】
|
階層型クラスタリングサービスでは、遺伝子(タンパク質)発現データのクラスター分析において、最も広範に使われているHierarchical Clusteringを用い、近いクラスター同士を融合するプロセスを繰り返し、樹形図を作成します。階層型クラスタリングの結果は、遺伝子(タンパク質)のクラスタリングとマイクロアレイのクラスタリングを同時に行い、二次元樹形図によって表示されます。樹形図による階層型クラスタリングによって、データに内在するグループ構造を視覚的に理解しやすくしてくれます。本サービスでは、Single
Linkage、Average Linkage、Complete Linkageの3種の階層クラスタリングに対応しています。 |
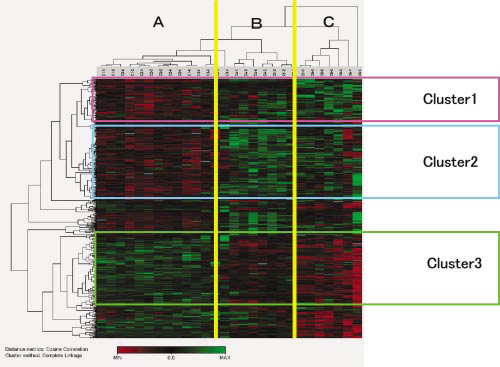
【Hierarchical Clustering】 |
| 提出データ |
解析対象となる実験データセット |
| 解析結果 |
クラスターの順位をつけたリストを作成し、お返しいたします。 |
| グラフ |
二次元樹形図 |
|
ここがポイント
| 本サービスでは、解析結果として右の様な二次元樹形図をお返し致します。(特徴的なクラスターの抽出は行っていません。)右図の様な、サンプル間(A,B,C)を識別できる様な特徴的なクラスター抽出を行い、さらに、Gene
Ontology/Pathway解析サービスで遺伝子群(タンパク質群)がどの様な機能を有するものが多いか、解析することで、各クラスターの解釈を深めることができます。 |
|
|
【非階層型クラスタリングサービス(SOM)】
|
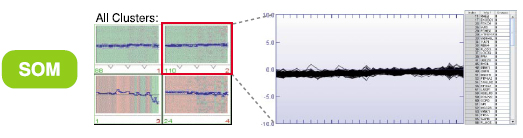
非階層型クラスタリングサービス(SOM)では、遺伝子(タンパク質)データを多次元空間から次元を下げて処理し(PCA)、プロット上で各ノード(中心点)から一定距離内にある遺伝子群(タンパク質群)を拾って、これをクラスターとして分類していきます(右図)。SOMの分類では(拾う遺伝子群(タンパク質群)を決定する)ノードからの距離を変えることによって、クラスター分けされる遺伝子数(タンパク質数)が変わるため、柔軟にクラスターを作ることができるのが特徴です。
| 提出データ |
解析対象となる実験データセット |
| 解析結果 |
各クラスター別の遺伝子リスト(タンパク質リスト) |
| グラフ |
PCA plot, Mean component plane, 各クラスター別のラインチャート |
|
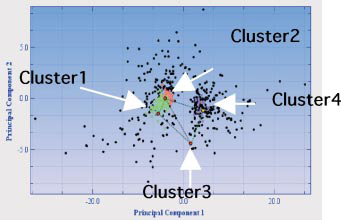
【PCA plot】 |
【Mean component plane】 |
 |
【非階層型クラスタリングサービス(k-means)】
|
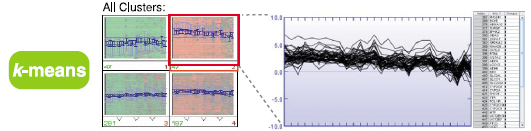
k-meansでは、任意に希望のクラスターの数を決め、その数のクラスターの代表点(重心)を配置するアルゴリズムによって、遺伝子群(タンパク質群)をいずれかのクラスターに分けることができます。
| 提出データ |
解析対象となる実験データセット |
| 解析結果 |
各クラスター別の遺伝子リスト(タンパク質リスト) |
| グラフ |
Mean component plane, 各クラスター別のラインチャート |
|
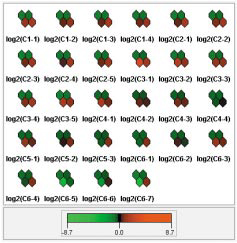 |
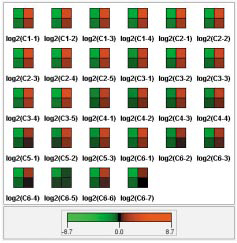
【Mean component plane】
| 各比較サンプルにおいて、4つのクラスターに属する遺伝子群の代表的な発現プロファイルの度合いを図示します。 |
|
 |
ここがポイント
| SOMとk-meansの違いは、任意のクラスター数か、n2(n=2~10)のクラスター数という分類数の違いだけではありません。例えば、上図では582種類の遺伝子(タンパク質)をk-means及びSOMで4つのクラスターに分けています。k-meansでは、遺伝子群(タンパク質群)をいずれかのクラスターにわけるため、各クラスター内の変動範囲は広くなり、SOMでは類似した発現パターンの遺伝子群(タンパク質群)のみをクラスターにしているため、各クラスター内の変動範囲は狭くなります。遺伝子群(タンパク質群)をすべて分類したいのであれば、k-meansとなりますが、全遺伝子(全タンパク質)から特徴的な発現パターンを得たいという場合においては、SOMがよく用いられています。 |
|
|
|
|
