製品・サービス情報
Ridom社製品 微生物ゲノム分子疫学解析ソフトウェア Bruker MBioSEQ Ridom Typer
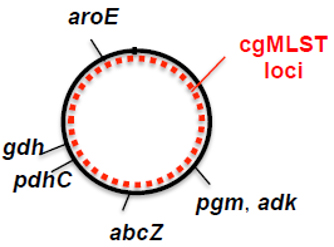
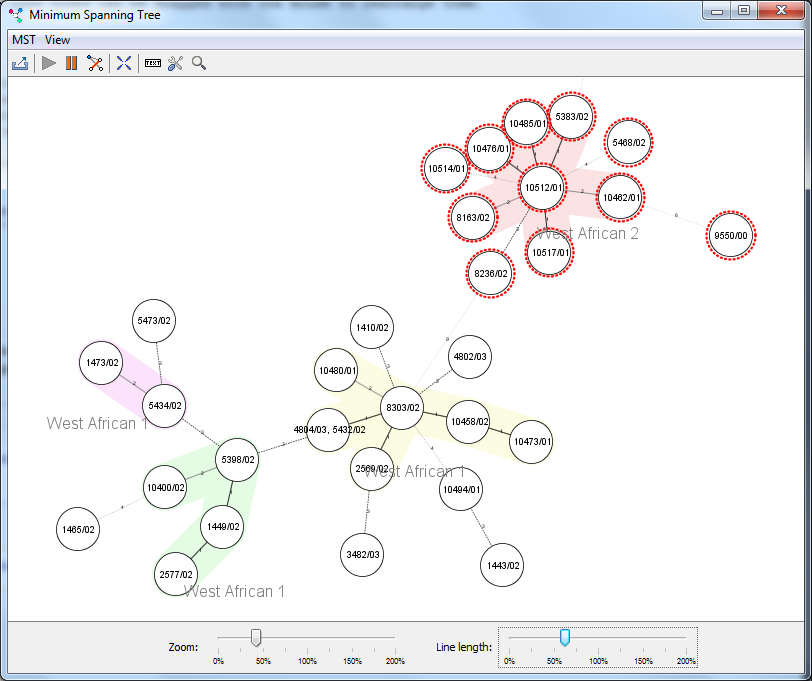
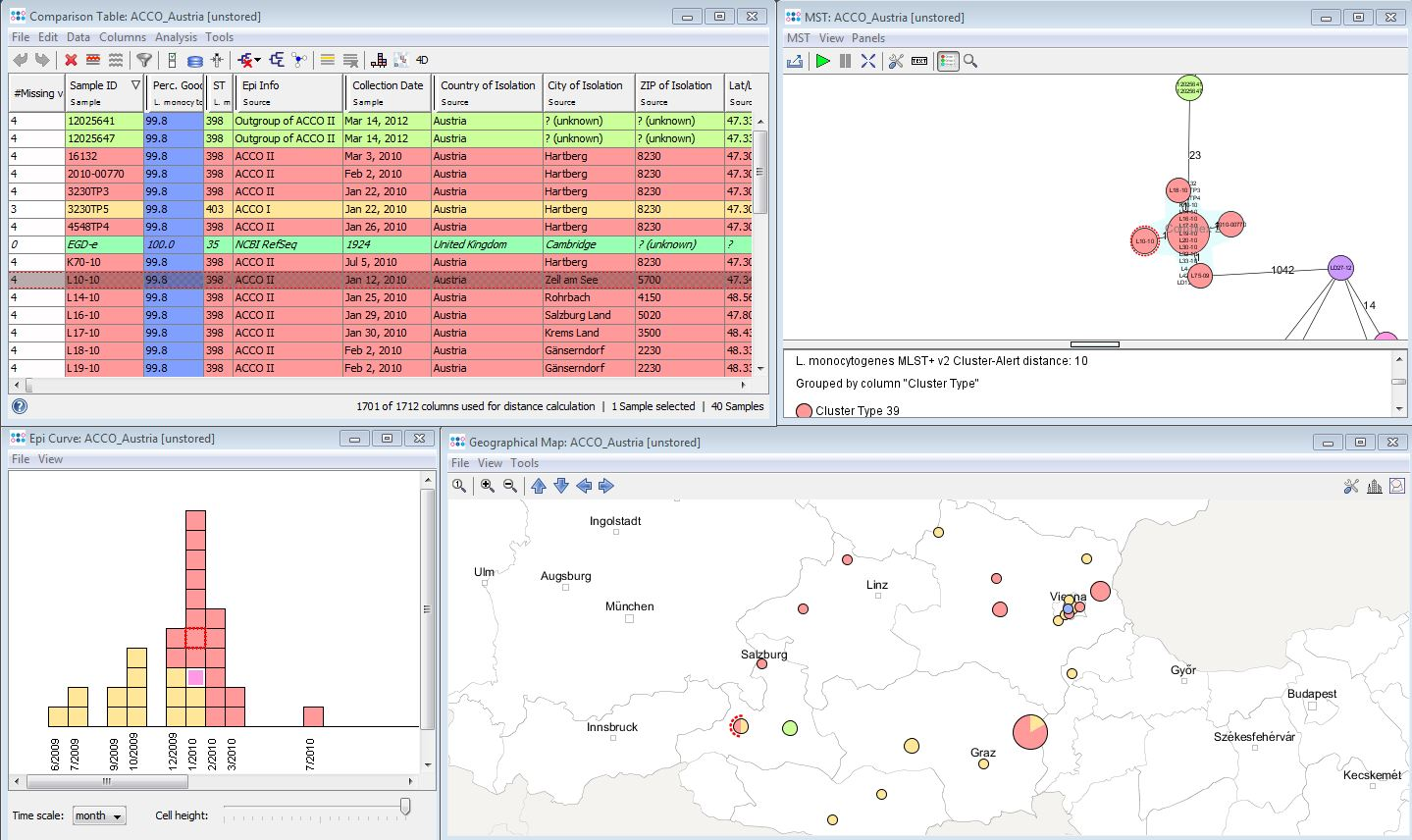
cgMSLT.org :Nomenclature Server)に用いられます。
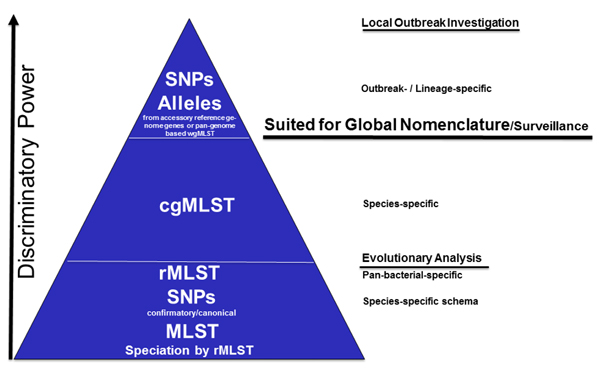
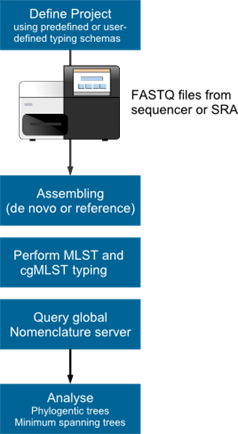
右図は、微生物ゲノムタイピングの階層ピラミッドを示しており、下から上に行くほど識別力があがります。種特異的なMLST法は、過去のデータとの互換性の理由で未だに使用されており(PNAS 1998, 95:3140[PubMed ])、MLST Sequence Types 情報(ST)は、NGSデータから用意に取得可能です。適切なソフトウェアと多様な細菌スキーマを使用した
ribosomal MLST法も、将来重要な役割を示すと考えられます(Microbiology 2012, 158:1005[PubMed ])。この様な従来型のMLSTコンセプトに対し、cgMLST法を用いたゲノムワイドの遺伝子情報による細菌タイピングは、明らかに拡張されています(e.g.,
PLos One 2011, 6:e22751[PubMed ] and Nature Rev. Microbiol. 2013, 11:728[PubMed ])。
VIDEO
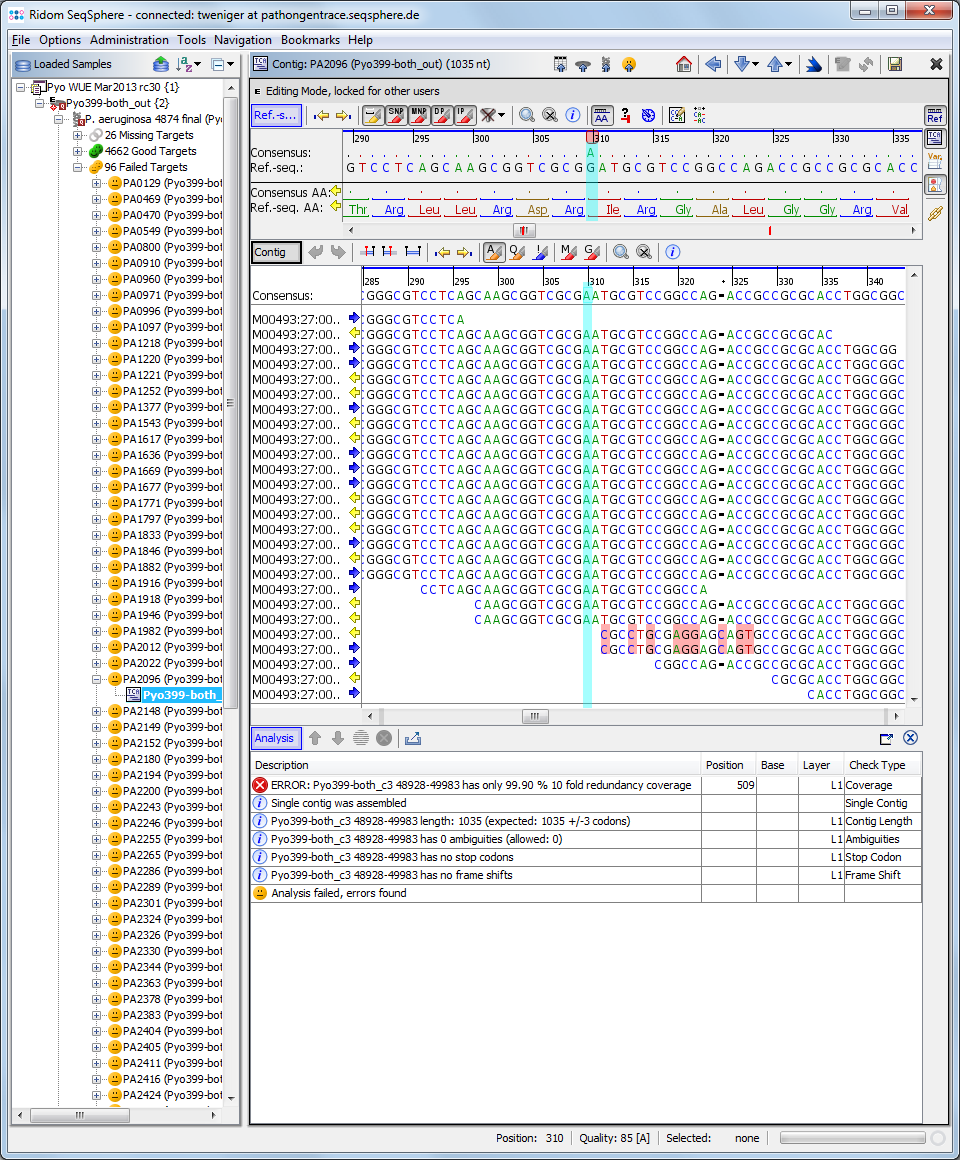
◆解析ツール
OS: Microsoft Windows 10/11, Microsoft Windows Server 2012 64-bit or later
RAM: 16-32GB
CPU: Quad-core processor or better
HD: 2-4 TB
OS: Microsoft Windows 10/11, Windows Server 2019 or later
RAM: 32GB
CPU: Quad-core processor or better
HD: 50GB以上
Internet connection required
重要: Ridom Typer クライアントで実行する一部の機能は、LinuxまたはWindows Subsystem for Linux
*ライセンスの種類については、弊社までお問合せください。
商品名 ライセンスタイプ 税別価格 Cat.#
Bruker MBioSEQ Ridom Typer 1年間ライセンス(2ユーザー)* アカデミック:お問合せ F-RD-A2-1Y
コマーシャル:お問合せ F-RD-C2-1Y
1年間ライセンス(5ユーザー)** アカデミック:お問合せ F-RD-A5-1Y
コマーシャル:お問合せ F-RD-C5-1Y
1年間ライセンス(30ユーザー)*** アカデミック:お問合せ F-RD-A30-1Y
コマーシャル:お問合せ F-RD-C30-1Y
3年間ライセンス(2ユーザー)* アカデミック:お問合せ F-RD-A2-3Y
コマーシャル:お問合せ F-RD-C2-3Y
3年間ライセンス(5ユーザー)** アカデミック:お問合せ F-RD-A5-3Y
コマーシャル:お問合せ F-RD-C5-3Y
3年間ライセンス(30ユーザー)*** アカデミック:お問合せ F-RD-A30-3Y
コマーシャル:お問合せ F-RD-C30-3Y
5年間ライセンス(2ユーザー)* アカデミック:お問合せ F-RD-A2-5Y
コマーシャル:お問合せ F-RD-C2-5Y
5年間ライセンス(5ユーザー)** アカデミック:お問合せ F-RD-A5-5Y
コマーシャル:お問合せ F-RD-C5-5Y
5年間ライセンス(30ユーザー)*** アカデミック:お問合せ F-RD-A30-5Y
コマーシャル:お問合せ F-RD-C30-5Y
* Ridom Typer クライアントより、2ユーザーまで同時にログインし、解析を実行できます。
** Ridom Typer クライアントより、5ユーザーまで同時にログインし、解析を実行できます。
*** Ridom Typer クライアントより、30ユーザーまで同時にログインし、解析を実行できます。
フィルジェンWebセミナー「コアゲノムMLSTスキーマの構築」(2024/1/18)
フィルジェンWebセミナー「全ゲノムシークエンスによる病原微生物の分子疫学解析」(2022/12/26)
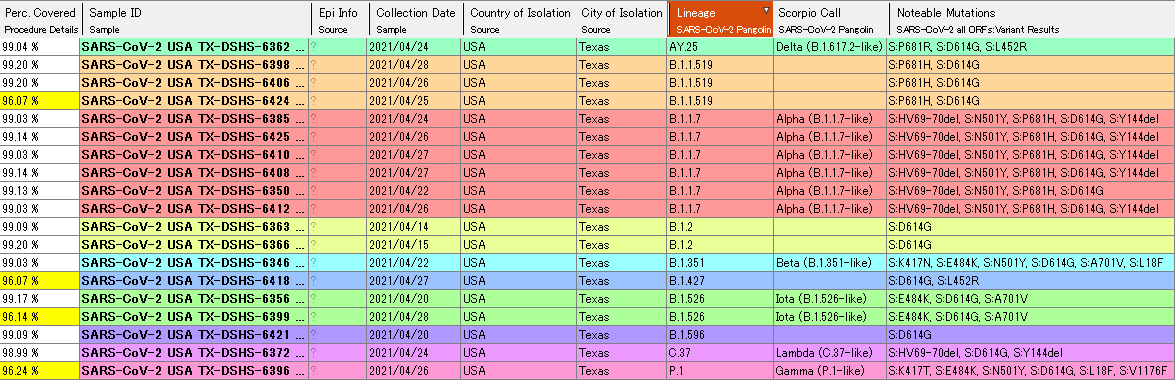
フィルジェンWebセミナー「新型コロナウイルスのNGS解析」(2021/7/7)