|
変動遺伝子(変動タンパク質)抽出サービスは、2比較以上のデータを対象としたサービスです。まず、個別の比較データから変動遺伝子(変動タンパク質)の抽出を行います。その後、複数の比較データに対して共通に変動している遺伝子群(タンパク質群)、あるいは、指定の比較データにおいて特徴的な遺伝子群(タンパク質群)の抽出を行います。Up変動とDown変動を分けた抽出結果をご提出致します。
|
|

(Up共通変動遺伝子リスト)
(Down共通変動遺伝子リスト) |
| 提出データ |
解析対象となる実験データ(テスト/コントロール)セット |
| 解析結果 |
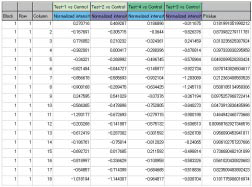
・実験毎の変動遺伝子(変動タンパク質)リスト
(2Up変動と2Down変動の2種類)
・共通変動遺伝子(変動タンパク質)リスト
・実験特異的変動遺伝子(変動タンパク質)リスト |
| グラフ |
スキャッタープロット |
|
(解析例1)
|
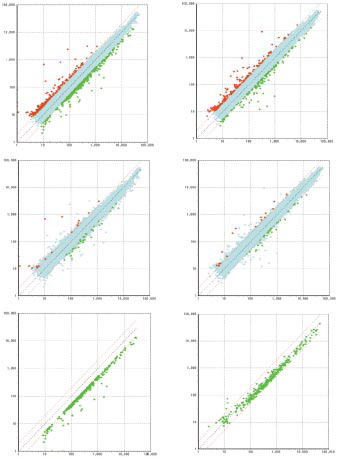
下記は、薬剤投与における経時変化の影響をマイクロアレイで解析した例です。左側が投与1時間、右側が投与3時間です。解析結果と合わせて、下図の様なスキャッタープロット図もご提出致します。
| 薬剤A投与1時間 |
薬剤A投与3時間 |
|
|
 |
(上図)
|
各実験において、緑のプロットがコントロールに対して2倍のUp変動を示し、赤色のプロットが2倍のDownを示しています。 |
(中図)
|
共通に2倍のUp変動をしているものを緑のプロット、共通に2倍のDown変動をしているものを赤のプロットで示しています。 |
(下図)
|
薬剤A投与1時間の実験のみで2倍のUp変動を示している場合です。この時、薬剤A投与3時間の実験では、これらの遺伝子はすべて2倍以下の変動となっています。 |
|
|
|
|
(解析例2)
|
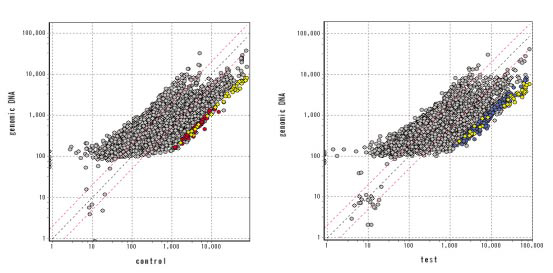
下記は、プロモーターアレイを用いたメチル化プロファイリングの解析例です。
ここでは、比較対象となるゲノムDNAのシグナルより、有意差のあるデータの抽出を行い、テストサンプルとコントロールサンプルで比較を行いました。
黄色のスポットは両方で有意差の認められた配列で、青色はテストサンプルで特異的な配列、赤色はコントロールサンプル特異的な配列となります。 |
|
 |
ここがポイント
| サンプル間の特徴を示す遺伝子群(タンパク質群)を抽出する場合に最適です。ここで抽出された遺伝子群(タンパク質群)について、さらに「Gene Ontology解析」や「Pathway解析」をすることで、機能的な解釈、生体内でのPathwayレベルの発現変化についての検討を加えることが可能となります。比較データが多い場合は、クラスタリングサービスもご利用ください。 |
|
|
|